

1. INTRODUCCIÓN
La protección de datos es una rama de la ciencia del derecho que abarca una gran cantidad de derechos a proteger de características muy diversas. La realidad social en la que los procesos tecnológicos cada vez se encuentran más implantados dentro de las sociedades actuales es un nuevo concepto que tenemos que abordar desde un punto de vista jurídico. Las nuevas tecnologías y las evoluciones de carácter o base tecnológica; todas ellas parten de un concepto básico de innovación técnica.
La innovación técnica derivada de una nueva tecnología presentada en sociedad puede acabar implantándose en un primer momento en el tejido social y empresarial. Pero la creación de innovación tecnológica no se arraiga de forma espontánea sin conocer una serie de motivaciones externas de forma que la misma haya sido capaz de movilizar a la sociedad para demandar colectivamente dicha innovación para la solución de un eventual problema más o menos "vital" para los ciudadanos, sino que por el contrario conlleva un proceso (Maksabedian, 1980). El arraigo viene tras un estudio de una sociedad la cual dependiendo del siglo y el momento histórico situado, se recogen todos los datos que en su momento la técnica coetánea al momento permita recoger y con un estudio de mismo se presenta un producto o servicio a dicha sociedad que mitigue esa necesidad. La presentación de ese producto o servicio es esa innovación técnica y ello incita a una modificación de la conducta social que o bien impide la implantación de esa innovación técnica por no ser finalmente tan necesaria o por el contrario esa innovación técnica facilita un cambio de paradigma social y el análisis de dichas necesidades permite por extensión que una tecnología se implante exitosamente en una sociedad de tal forma que genere un nuevo consenso social en torno a un nueva necesidad social ya no imperante sino arraigada y sólida.
El proceso social de arraigamiento de una tecnología y los pasos que debe seguir esa tecnología para poder considerarse parte de una sociedad se divide en diez pasos, los cuales toda tecnología a lo largo de la historia han tenido que recorrer. Por ello necesitamos conocer como se genera al arraigamiento tecnológico en una sociedad para poder realizar un análisis de las teorías jurídicas doctrinales que se generan en torno a una tecnología y cómo influye en la sociedad. La necesidad de reflexionar doctrinalmente acerca de si una legislación es acorde a la realidad del progreso social tecnológico es un elemento con cada vez mayor peso, debido al problema que se avecina con las nuevas tecnologías y la gestión de los datos privados.
Por todo lo anterior y tomando como base lo indicado en capítulos precedentes el proceso social de arraigamiento tecnológico o progreso social tecnológico se podría definir como aquella innovación técnica generada tras la aceptación de la existencia de una necesidad social para la cual se busca una solución de base tecnológica. Todo esto tiene una finalidad en la que la sociedad adopta como suya dicha innovación con el objetivo de generar una aplicación práctica de la misma para alcanzar una solución o mejora a un problema social. Como consecuencia, dicha innovación tecnológica se integra en la sociedad y diseminándola por ella con el fin de generar un arraigo de la tecnología desarrollada que tras un tiempo de uso y por la propia obsolescencia del concepto tecnología y derivada de su naturaleza intrínseca derive en otra nueva innovación que reinicie el ciclo de arraigamiento de otra nueva tecnología para solucionar los nuevos problemas sociales generados.
Todo este proceso de arraigamiento tecnológico conlleva, en todo caso, un análisis de datos previo, durante y después. Los datos que se analizan son los mal llamados Datos Personales, puesto que la nomenclatura correcta es Data Privacy o Datos Privados, como a partir de ahora los llamaremos. Los datos personales son una tipología o parte de los Datos Privados o del Data Privacy de un ciudadano. Toda esta realidad teórico jurídica, se mueve dentro de la doctrina y todos sus postulados teóricos, actualmente el postulado doctrinal o la teoría más aceptada para la protección de los datos privados, es la Teoría de Mosaico de Madrid Conesa que se encuentra vinculada al concepto datos personales.
Toda teoría va precedida de una realidad social, esa realidad social es la que permite construir un paradigma que posteriormente y fundamentado se convierta en una teoría que pretenda dar respuesta a ese paradigma existente. Por ello, la contextualización de una teoría jurídica es un aspecto muy importante y preciso conocer para evaluar su actual nivel de cobertura social. Los sistemas tecnológicos actuales son cada vez más avanzados y recaban más información, por ello los ciudadanos necesitan de una herramienta profunda y actual que les proteja jurídicamente. La sociedad ha tenido una serie de cambio que como luego veremos, ha generado un nuevo paradigma, que da cobertura para una nueva teoría sobre protección de datos privados que se adapte a las necesidades actuales.
Teniendo en cuenta todo lo indicado y partiendo de los diferentes antecedentes mencionados, los objetivos del presente capítulo tienen como intención ofrecer los argumentos científicos competentes para construir una nueva teoría de protección de datos privados que mejore doctrinal y jurídicamente el actual panorama respecto a los datos privados y el tratamiento que a estos se le realizan recaptados y transmitidos a través de redes, IOT, IORT o cualquier otro dispositivo todo ello en perspectiva al ordenamiento jurídico internacional. Por otro lado, en segundo lugar, se va a analizar la situación actual de la principal teoría existente en materia de protección de datos personales, la Teoría del mosaico para posteriormente todo ello ponerlo en perspectiva al punto de vista jurídico obtenido en el objetivo primero con la propuesta de un nuevo marco teórico de desarrollo para la protección de datos privados. La finalidad del objetivo segundo es analizar las situaciones jurídicas actuales respecto a cómo el tratamiento de la protección de datos privados o personales, dependiendo del marco teórico de referencia, cual está correctamente representado en la sociedad actual como eje protector de la misma. Asimismo, como hemos visto anteriormente en otros capítulos se analizará de qué modo afecta a la protección jurídica de dichos datos todo lo expuesto y cuál es la repercusión que tienen estos respecto a su tratamiento versus a la privacidad de los mismos en concurrencia con el derecho natural así como los derechos de usuarios y ciudadanos.
Por ello, en tercer lugar se quiere realizar una vez expuestos los dos objetivos anteriores un análisis de la situación de que marco teórico es el más correcto teniendo en cuenta la función que debe des-empeñar que no es otra que encaminar el legislador como eje vertebrador de las normas y con el objetivo de subsanar los déficits que existan tanto técnicos como jurídicos, los cuales arrastran las normativas actuales normativas tras usar un marco teórico bajo un paradigma obsoleto en su fundamentación de base y por ende el actual riesgo jurídico que corren los ciudadanos respecto a la custodia, tratamiento y finalidad de sus datos en concurrencia con los diferentes derechos que les amparan a dichos ciudadanos.
Asimismo, para finalizar como cuarto objetivo, se va a realizar una labor de análisis global a modo de conclusiones a fin de localizar las posibles incongruencias entre el marco teórico actual, el nuevo marco teórico propuesto y el factor de riesgo existente respecto a la génesis principal que es el ámbito de aplicación de la protección de datos privados de los ciudadanos y la pretensión básica de todo marco teórico que no es otro que intentar brindar una univocidad doctrinal que permita elaborar una normativa lo más acorde a la realidad en materia de tratamiento de datos privados. Tras realizar dicho análisis, se terminará concluyendo cual es la realidad jurídica de todo ello y la situación actual teniendo en cuenta el auge en materia de tratamiento de datos privados del IOT, el IORT y el data mining así como el machine learning, siendo todos ellos piezas clave dentro del nuevo marco teórico que debe dar respuesta a todos los restos actuales y vertebrar el futuro de la explotación de datos privados.
Por ello, la metodología empleada para el presente capítulo es una metodología basada en la investigación analítica. Por ello, el desarrollo que se va a presentar a continuación se basa en una investigación jurídico-proyectista con naturaleza propositiva y bajo un sistema que emplea fundamental-mente un método inductivo-comprensivo con diferentes momentos en los que se usará una metodología hipotético-deductiva para la exposición del nuevo marco teórico acorde a la propuesta teniendo en cuenta la respuesta al paradigma actual. La pretensión metodológica jurídico-proyectista pro-positiva tiene su principal finalidad conseguir averiguar la evolución del marco jurídico que lleva implantado desde hace años con la actual Teoría del Mosaico de Madrid Conesa y la protección de datos respecto a la génesis teorética en perspectiva al objetivo a proteger que son los datos de las personas y la causa de los déficits protectores teniendo en cuenta los marcos teóricos.
Por ello, cabe realizar un análisis profundo de la situación actual. Esto permite alcanzar a ver la situación actual y nos invite a ser partícipes de un cambio de paradigma jurídico que revolucione la doctrina que a fin y al cabo la que impulsa la elaboración de las normas poniendo los cimientos de toda norma escrita.
2. CONCEPTOS
Para poder abordar la justificación de la necesidad de un nuevo marco teórico y comprender el constructo jurídico de las diferentes conceptualizaciones en base a la solución a los nuevos paradigmas, resulta necesario explicar una serie de conceptos de forma profunda. A lo largo de los capítulos hemos ido explicando en cada uno de ellos diferentes conceptos, en ocasiones se repite el mismo, pero cada vez la conceptualización es más profunda. La idea consiste en generar una progresividad en la profundidad de los conceptos para asimilar el máximo de conocimientos acerca de los conceptos de una ciencia. La pretensión es una formulación básica que persigue alcanzar a comprender la génesis jurídica que estamos construyendo sobre una nueva teoría sustitutiva a la Teoría del Mosaico. Por todo ello, resulta necesario, definir que es un paradigma, la diferencia conceptual entre Data Privacy y Datos Personales o Data Protection, Data Mining en relación al Linked Data, la Inteligencia Artificial y el Machine Learning.
Todo cambio social conlleva aparejado una serie de problemas que necesitan ser resueltos por las diferentes ramas científicas que vertebran la sociedad. La ciencia usa para ello los paradigmas que no son otra cosa que proposiciones teórico-científicas con carácter de universalidad, con un amplio reconocimiento de su validez, que durante un tiempo determinado y sostenido proporcionan modelos de solución a modelos de problemas. Los cambios sociales y las transformaciones profundas se nutren para su correcto desarrollo de paradigmas, que no es otra cosa que revoluciones científicas que revolucionan el patrón usual hasta un momento determinado sustituyéndolo por otro que da mejores soluciones a un problema determinado y permite la continuidad del desarrollo de una ciencia. (Kuhn, 1992).
Por lo que respecta a la Protección de Datos o Datos Personales, considerarlo como el eje principal vertebrador de la doctrina jurídica sobre la protección de los datos de un ciudadano es un error de base conceptual. El Data Privacy es el derecho básico conceptual correcto, el Data Privacy es el derecho a proteger y el Data Protection o Protección de Datos es la herramienta que se usa para proteger, objeto a proteger vs herramienta a usar. El concepto Data Privacy es el concepto origina-rio correcto, las traducciones de dicho concepto por Protección de de Datos o Datos Personales son erróneas puesto que los datos personales son un tipo de dato dentro del Data Privacy y la Protección de Datos como indicábamos es una herramienta. Por ello, y no obstante independientemente de las discusiones acerca de si su uso indistinto en las legislaciones otorga la misma significancia al objeto protegido, lo cual no es igual, nos debemos parar en la nomenclatura derivada de su traducción como hemos indicado. Para poder entender posteriormente la teoría objeto de presente capítulo y sucesivos.
El Data Privacy en primer lugar necesita definir dentro de su conocer su alcance conceptual cuatro características claros derivadas por su naturaleza. Las cuatro características básicas que debe contener cualquier teoría actual de Data Privacy son (Bertino, 2016):
- Derecho a la supresión total de datos y Derecho al olvido como dos derechos diferente-mente configurados
- Regulación de las decisiones automatizadas y del autoperfilado de datos privados
- Regulación específica separada del Data Privacy y el Data Protection, generando un espacio propio regulatorio del Data Protection como herramienta multimodal protectora del Data Privacy.
- Evaluación continúa del alcance de los sistemas de protección jurídica al Data Privacy y al Data Protection.
Así mismo nos encontramos con la necesidad de definir un subconcepto dentro del Data Privacy evolucionado del original, debido al cambio social por las nuevas tecnologías. El Data Differential Privacy o Privacidad Diferencial de Datos (Dwork, 2006). La privacidad diferencial es una concepto que se aplica a los algoritmos de tratamiento de datos en Data Mining y Machine Learning. El Data Differential Privacy o Privacidad Diferencial de Datos es el conjunto de reglas y órdenes que se deben de establecer en base a los parámetros del Data Privacy para conseguir una estabilidad algorítmica a la hora de explotar los datos privados. Las reglas consisten en una serie de pequeños cambios en la entrada de un algoritmo, de forma que se restrinjan de forma automatizada la receptación de ciertos datos con la finalidad de impedir la identificación de a quién pertenece ese dato, de forma que sólo se induzcan solo pequeños cambios en la distribución de las salidas de los datos recaptados tras su estudio.
Tras analizar todo ello una de las conclusiones respecto al concepto básico de Data Privacy y Data Protection como elementos que vertebrarán cualquier doctrina o regulación jurídica debemos realizar ciertas apreciaciones respecto a cómo se debe unir ingeniería y derecho en un solo corpus iuris. El análisis realizado nos debe encaminar hacia una dirección científica donde se integren tanto conceptos legales como conceptos técnicos respecto Data Privacy (como conceptos legales) y Data Protection (como conceptos técnicos recogidos en la legislación aplicable al Data Privacy). Partiremos de la base de que ambos campos, el legal y el técnico, abordan la privacidad desde diferentes perspectivas; pero con la esperanza de que se regulen en un solo marco común jurídico. El correcto desarrollo de ello debe contemplar el cumplimiento de las siguientes necesidades (Sokolovksa & Kocarev, 2018):
- Adaptación de los actuales conceptos legales ambiguos técnicamente y legalmente hacia una conversión que permita aplicar nociones matemáticas concretas sobre los datos privados.
- Elaboración de todo el contenido legal de los niveles de privacidad necesarios técnicos para todos los sistemas de explotación y tratamiento de datos.
- Regulación jurídica de la pérdida de información derivada de causas tecnológicas, midiéndolo por una serie de metodologías a aplicarse.
- Evaluación de la viabilidad técnica de una propuesta normativa y su complejidad real res-pecto al derecho a proteger y la búsqueda de alternativas protectoras legales que simplifiquen los desarrollos técnicos.
La necesidad de una definición conceptual por lo tanto no es una excepción en el ámbito de la “protección de datos” o Data Privacy como acabamos de ver. El concepto original reconocido doctrinal y jurídicamente a nivel mundial es Data Privacy y el que se expone en todos los países de forma genérica independientemente de la lengua. No obstante, existe en muchos países una discusión doctrinal acerca de privacidad e intimidad, pero no es su nomenclatura, sino en su definición y alcance posterior, aunque ulteriormente sean prácticamente idénticos en lo que a protección real perseguida por la norma se refiere, donde se halla el verdadero nudo gordiano. Por ello, el problema radica en que se emplea en muchas ocasiones de forma indiferente Data Privacy y Data Protection, como sinónimos que pretenden decir lo mismo. La realidad es que no son lo mismo, el Data Privacy pretende proteger los datos privados de la utilización indebida regulando su correcto uso, recolección, borrado total o parcial, así como almacenaje y tratamiento de los mismos. Por el contrario el Data Protection serían los métodos o políticas de seguridad todo ello a nivel técnico y regulado legal-mente; establecidas para asegurar la correcta protección del Data Privacy (Gellert & Gutwirth, 2013).
La traducción del concepto Data Privacy que es el término legal correcto; no ha sido el de “Privacidad de Datos” sino “Protección de Datos” usando el concepto Data Protection. El uso del concepto Data Protection análogo a Data Privacy es un error puesto que la naturaleza jurídica a este campo del derecho la otorga la Data Privacy no la Data Protection. La realidad de traducir atribuyendo como objetivo principal ulterior a una legislación el concepto “protección de datos” en lugar de “privacidad de datos” es un error básico. Si construimos toda la legislación entorno a la herramienta usada que debe ser regulada posteriormente y no el objeto a proteger, estamos partiendo de una premisa errónea.
Asimismo, en muchas ocasiones, se da como equivalente privacidad e intimidad y se dan a entender como sinónimos de un mismo concepto y que vienen a tener el mismo significado en lo que a protección de datos se refiere. Por ello, resulta también aquí necesaria una distinción entre ambos conceptos de privacidad e intimidad. La distinción radica principalmente en que la intimidad pertenece al ámbito de la privacidad debido a que todo aquello podemos considerar íntimo por extensión es considerado privado. Pero al contrario no toda la información privada se puede considerar información íntima (Pierini, Lorences y Tornabene, 2002). Por otro lado, tenemos el Data Mining y el Linked Data, ambos conceptos los analizaremos de forma independiente y a fondo en posteriores capítulos cuando se expliquen de forma comparada porque la actual Teoría que estamos exponiendo la "Theory Modular Data Privacy" o "Teoría Modular de Datos Privados" debe ser la sucesora de la actual Teoría del Mosaico.
Por ello, el Data Mining o KDD (Knowledge Discovery in Database) o KMD (Knowledge Mining From Data) dicho de forma más descriptiva, es un proceso que tiene como objetivo el tratamiento de grandes volúmenes de datos. El Data Mining en sí mismo es una metodología de explotación e interpretación de datos, de los cuales por diversos fines u objetivos resulta necesario extraer información. La extracción de la citada información y por ello el uso de ésta metodología de explotación de datos es que se extra información de grandes volúmenes de datos, por lo que es una tarea muy difícil. Para ello Data Mining, KDD o KMD tiene como objetivo principal en su base jurídico analítica la búsqueda de patrones de información partiendo de datos existentes en diferentes bases de datos. Para esta finalidad usa sistemas estadísticos, machine learning o patrones de reconocimiento a través de algoritmos de extracción de información, dividido en siete fases que más adelante se explicarán (Alasadi, 2017). A pesar de ello, cabe recordar que ésta técnica de extracción de información se implantó a la par de las primeras investigaciones en computación avanzada puesto que la computación nació en la segunda guerra mundial. Por lo que en realidad no es nuevo y se trata de una rama de la inteligencia artificial que nació en 1960, inspirado en la máquina enigma de Alan Turing.
Si por ello realizamos un análisis de la definición de Data Mining, podemos concluir que es una técnica de carácter exhaustivo, con una serie de pautas, bajo una orden de tendencias y correlaciones cuyo fin es conocer la realidad del dato que analizan o buscan. El Data Mining, como sistema de explotación de Data Mining, todos los datos que analizan pasan por siete fases (Kamber, Pei, 2011). Asimismo estas siete fases se deberían agrupar en cuatro zonas:
Recepción de datos
1.- Data Cleaning
2.- Data Integration
Procesamiento de datos
3.- Data Selection
4.- Data Transformation
Aplicación de metodologías de Data Mining
5.- Data Mining
Evaluación y resilencia
6.- Pattern Evaluation
7.- Knowledge Presentation
El Linked Data a su vez se encuentra vinculado al Data Mining y es otra metodología de estudio y organización de datos complementaria. El Linked Data es el sistema de diseño de infraestructura de datos bajo una serie de reglas estandarizadas para cualquier fabricante, lo cual permite confirmar la que la finalidad de las recaptaciones o generaciones de datos primarias del Data Mining se ha con-seguido. Por esta razón, se podría decir que sería como un sistema de auditoría (Ríos Hilario, Martín Campo y Ferreras Fernández, 2012).
A continuación, tenemos a la Inteligencia Artificial como los mecanismos basados en hardware y software que tienen la capacidad de toma de decisiones asistida o no asistida, con el objetivo de desarrollar una serie de tareas y funciones básicas programadas por un operador humano, el desarrollo de diferentes tareas preprogramadas; o que bajo condiciones de funcionamiento autónomo y con libre albedrío sean capaces de seguir unos objetivos tomando las decisiones de forma independiente al ser humano; siempre en todo caso para fines socialmente correctos, no violentos, y que no sean nocivos; ni para humanos ni para los propios robots (Nisa Ávila, 2016).
A su vez dentro del concepto de Inteligencia Artificial nos encontraríamos con el de Machine Learning, como un subsistema independiente de la Inteligencia Artificial, que usa algoritmos y una gran cantidad de datos recogidos para entrenar a la máquina con Inteligencia Artificial a mejorar los resultados para los que está programada procesando los datos y la información, enseñando a la máquina a generar una toma de decisiones en base a esos datos entrenados. El Machine Learning tiene la capacidad de ser dinámico, siendo capaz de automodificar su programación para mejorar sus resultados, todo ello gracias al Deep Learning (Jakhar & Kaur, 2020).
3. LA THEORY MODULAR DATA PRIVACY O TEORÍA MODULAR DE DATOS PRI-VADOS UN NUEVO MARCO TEÓRICO PARA LA PROTECCIÓN DE DATOS PRIVA-DOS
La sociedad ha cambiado, la ciencia ha avanzado muchísimo y la tecnología ha redefinido nuestra forma de afrontar nuestra vida en todos sus aspectos. Por tanto, esto nos arrastra a una nueva situación que cuando se definió la Teoría del Mosaico en 1984 no existía. El cambio social, nos conlleva a un cambio de paradigma y muestra la necesidad de un nuevo marco teórico donde refundar la forma de enfocar la gestión jurídico-legislativa del Data Privacy y todo lo que ello conlleva en el ámbito del Data Protection. Todo esto se debe a las nuevas tecnologías que recaptan información de muy variadas fuentes y que gracias al Data Mining, la Inteligencia Artificial y el Machine Learning explotan y procesan con diferentes fines gracias al Deep Learning, que antaño eran de ciencia ficción, pero ahora son reales. Por todo lo expuesto, se necesita un nuevo marco teórico que de res-puesta con un nuevo paradigma, ese nuevo marco teórico es la Theory Modular Data Privacy o Teoría Modular de Datos Privados.
En la Teoría de las Esferas como indicábamos en capítulo anteriores, los datos se organizaban en círculos concéntricos. El aspecto más personal en la que se encontraban los datos más íntimos de un individuo correspondían a un círculo que estaría en la zona más cercana al individuo, lo privado en un círculo más amplio y así sucesivamente. Madrid Conesa sin embargo teorizó casi 30 años después de la Teoría de las Esferas otro nuevo sistema que daría otro nuevo paradigma a la ciencia del Data Privacy. Por ello Madrid Conesa indicó que el sistema de protección de datos en base a círculos con las tecnologías de 1984 eran ineficaces y formula un nuevo concepto llamado Teoría del Mosaico. La Teoría del Mosaico considera que la información de un individuo en cuanto a lo privado y lo público son datos abiertos y no pertenecientes al 100% a un apartado determinado. Por ello se puede entender que existe una delgada línea entre los datos que se pueden considerar privados y cuales públicos, puestos que esa clasificación según Madrid Conesa va a depender de quien sea el sujeto receptor de la información y quien el emisor de la misma, era necesario un cambio. Por otro lado lo que en un principio puede parecer un dato irrelevante, como el sexo de una persona, el nombre, la fecha de nacimiento, sus inclinaciones políticas, sus datos de renta, etc si se presentan aislados; si los mismos en lugar de verlos de forma aislada los unimos, todo cambia. Los datos que a priori pueden parecer no importantes y que no afectan al derecho a la intimidad si los conectamos con otros que quizás tampoco parezcan irrelevantes, pero que pertenezcan al mismo individuo, podemos llegar a conseguir una composición exacta de dicho individuo sin que éste tenga conocimiento de ello. Por tanto sucede “al igual que ocurre con las pequeñas piedras que forman los mosaicos, que en sí no dicen nada, pero que unidas pueden formar conjuntos plenos de significado” (Miguel, 1994).
El conjunto de pleno significado que se teorizaba en su momento por parte de Madrid Conesa en 1984 resulta necesario que sea actualizado al igual que sucedió con la teoría de las esferas alemana. La teoría del mosaico tras todos los datos que estamos analizando debería evolucionar con una nueva versión que podríamos denominar “Teoría modular de Datos Privados” o “Theory Modular Data Privacy”.
La “Theory modular data privacy” es en el campo jurídico teórico del ámbito de Data Privacy y Data Protection el fiel reflejo jurídico teórico del actual sistema de explotación de datos que se usa en la actualidad para la explotación de datos por parte por ejemplo de las grandes corporaciones y gobiernos entre otros. La actual tecnología, a diferencia de lo que indicaba la Teoría del Mosaico, elabora una composición a tiempo real de cada individuo donde uniendo diferentes piezas de datos de diferentes fuentes, sistemas, orígenes y lugares de forma que consiguen averiguar diferentes situaciones reales diferentes, simultaneando y combinando los mismos datos con otros de forma repetida o única para averiguar todo lo relativo a la privacidad de un individuo.
La “Teoría modular de Datos Privados” a diferencia de la “Teoría del Mosaico” donde directamente los datos sin ningún tipo de pretratamiento ni postratamiento se ensamblan directamente sin refinar en ese mosaico indivualizado para identificar un aspecto concreto de un usuario. La “Teoría modular de la privacidad de datos” va mucho más allá al ser más compleja derivada de las tecnologías actuales. La Theory modular data privacy o Teoría modular de Datos Privados pretende reflejar la realidad que actualmente se usa para alcanzar dichas recreaciones de datos privados de individuos. La Theory modular data privacy o Teoría modular de Datos Privados vendría a definir un nuevo marco teórico donde los datos se usan primero como combustible para una “máquina” que se dedica a recrear la vida privada de los individuos con diferentes finalidades gubernamentales o comerciales arrojando una serie de datos más complejos que los que en sus inicios recogió.
La Theory modular data privacy parte de la base que los datos actualmente no sólo se usan en bruto como en la Teoría del Mosaico, sino que se depuran y transforman de forma previa a su tratamiento y por lo tanto ya no forman sólo un mosaico estático sino que es algo dinámico y vivo. Ésta “máquina” que propone como ejemplo para explicar el marco teórico de la “Teoría modular de la privacidad de datos” o Theory modular data privacy procesa los datos de los individuos. La máquina está compuesta por diferentes módulos que encajan entre sí para funcionar y que de forma independiente no pueden tratar los datos por lo que si falta uno de esos módulos se rompe la “máquina”, deja de funcionar y no se obtiene el producto final, que no es otra cosa que la reconstrucción del Data Privacy de los individuos con o sin su consentimiento a tiempo real y en todos los aspectos privados de la persona, de forma que permitan conocer la evolución individual personal de cada individuo sometido a análisis. El consentimiento es otro de los puntos de divergencia con la Teoría del Mosaico, entonces en 1984 no existían aplicaciones o sistemas de hardware que usaran IOT o APPS móviles que monitorearan, recaptaran datos y todo ello bajo una red compleja de obtención de datos bajo una deficitaria normativa que impide conocer realmente a los individuos que se recaba realmente de forma comprensiva.
En el siguiente esquema de elaboración propia podemos ver la Theory modular data privacy o Teoría de Modular Datos Privados la cual se compone por cuatro módulos que funcionan de forma secuencial y repetitiva donde al acabar de analizar los datos todo vuelve a comenzar por el paso 1. La Theory modular data privacy pretende establecer un marco individualizado de regulación legal para cada uno de esos módulos para así de esa forma con la construcción de este nuevo marco teórico dar respuesta a las necesidades actuales entorno a la protección del Data Privacy de forma específica con una regulación legal por módulo para posteriormente poder elaborar un marco común de referencia de Data Privacy.
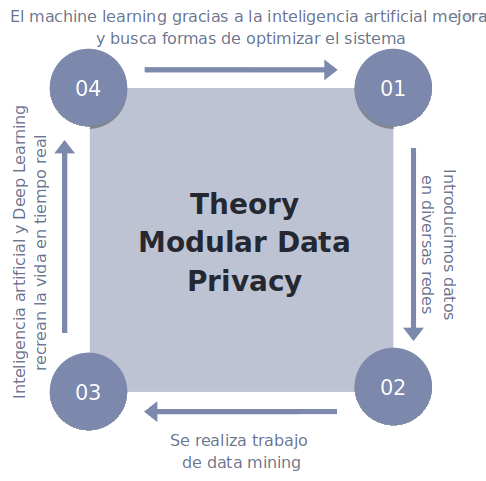
El paso primero se encontraría protagonizado por el individuo que introduce datos tanto voluntarios como involuntarios en diferentes redes. Los datos que el individuo vuelca a las redes a través de diferentes sistemas conectados a internet, genera un input de datos en bruto de diferentes fuentes y tipologías que resulta necesario depurar. Posteriormente, nos encontraríamos con el paso 2 donde gracias a un proceso de data mining, se depuran los datos volcados y tras un proceso complejo de siete fases en cuatro zonas se obtienen todos los datos importantes secuenciados según el objetivo perseguido pero sin una estructura concreta y precisa. En la tercera fase, gracias a un sistema de inteligencia artificial, se relacionan todos los datos en base a una serie de parámetros que previa-mente se han configurado creando un producto final y se recrea una “secuencia viva de la privacidad del individuo” con capacidad de actualización a tiempo real del mismo como si fuera una video a tiempo real pixel a pixel en streaming y cuyos datos permite obtener un rendimiento a quien los explota. Posteriormente, en una cuarta fase, gracias al machine learning, se depuran los posibles fallos localizados y se introducen medidas correctoras en los pasos 1, 2 y 3 que permita mejorar un mejor producto final a quien explota los datos. Por ello el dinamismo de la explotación de datos en la actualidad no es la misma que cuando se teorizó la Teoría del Mosaico y por ello debido al cambio de paradigma, resulta necesario adoptar el nuevo marco teórico expuesto.
En el ámbito del derecho y el campo jurídico de la protección de datos y los datos privados lo que describe la “Theory modular data privacy” es lo que está sucediendo en el ámbito de las redes y el tráfico de datos, por lo que se convierte en los cuatro puntos cardinales a proteger jurídicamente en materia de protección de datos. Por este motivo, cada módulo de los cuatro módulos de esta "máquina" debe estar regulado de forma independiente bajo a su vez un marco general.
Es necesario resaltar que un dato aislado no es un problema, el problema radica en el conjunto de datos que se vuelcan y como se pueden ir engarzando entre sí como si de un collar de perlas se tratase. El mosaico era estático una fotografía, ahora los datos debido a la gran capacidad de generación y análisis todo está en constante movimiento, es un video en streaming. Todo ello se completa con la cesión de datos entre empresas lo que permite conseguir una mayor fidelidad de los datos y la evolución jurídica de un postulado teórico del mosaico a otro donde la evolución tecnológica recrea la vida de las personas con datos con una precisión extraordinaria a tiempo real. Posteriormente, en capítulos sucesivos se desagregarán los cuatro pasos de forma más pormenorizada.
4. CONCLUSIONES
La sociedad se encuentra en constante movimiento, y genera una cantidad ingente de datos incapaces de ser analizados. El desconocimiento por parte de la población de los datos que ellos mismos vuelcan a la red, de todo tipo se convierte en un arma de doble filo, que facilita la vida a los ciudadanos, pero que como contraprestación les permite está más controlados.
Las tecnologías de la información y la comunicación, ha conllevado un gran cambio de pensamiento social. Las tecnologías emergentes de los años 60 no tienen nada que ver con las tecnologías existentes en los 80 y abismalmente diferentes a los del 2020. La progresividad de avance en la computación si aplicamos la Ley de Moore nos ofrece un horizonte de sucesos en el que la tecnificación humana y por extensión social es un eje a tener en cuenta para la regulación de las relaciones humanas por parte del ordenamiento jurídico de cualquier entra nacional o supranacional.
La necesidad de un marco teórico que siente las bases necesarias para afrontar dichos cambios con una fundamentación jurídica sólida es un elemento obligatorio. La refundición de la doctrina y los cambios de paradigma son una necesidad dentro de una ciencia. La ciencia que se ancla en un mismo paradigma y no tiene la necesidad de debatir sobre otros que lo sustituyan o le aporten nuevos enfoques, es una ciencia abocada a la desaparición.
La actual Teoría del Mosaico, es una teoría que tiene carencias derivadas de la diferencia de tecnologías sobre la que su marco teórico se fundamentaba, lo cual genera una inseguridad doctrinal al no contemplar el escenario actual de donde se nutren los datos. La analogía en la doctrina no tiene sentido y aplicar parches derivados de interpretaciones por analogía no se puede permitir, para ello se reformulan teorías o se pronuncian otras nuevas si la reformulación es muy profunda. Por ello la razón de la nueva Theory modular data privacy.
El horizonte de la sociedad es el de las nuevas tecnologías, la robótica y la inteligencia artificial, ahora más que nunca necesitamos una doctrina que permita a los legisladores construir el futuro legal que vertebre la sociedad sobre los cimientos de un marco teórico sólido que los guíe. No podemos olvidarnos, que la doctrina es el eje sobre el que se construyen las políticas legislativas, son el padre del todo jurídico en derecho.
BIBLIOGRAFÍA
Alasadi, S. A., & Bhaya, W. S. (2017). Review of data preprocessing techniques in data mining. Journal of Engineering and Applied Sciences, 12(16), 4102-4107.
Bertino, E. (2016, June). Data security and privacy: Concepts, approaches, and research directions. In 2016 IEEE 40th Annual Computer Software and Applications Conference (COMPSAC) (Vol. 1, pp. 400-407). IEEE.
Dwork, C. (2006). Differential privacy, in automata, languages and programming. ser. Lecture Notes in Computer Scienc, 4052, 112.
Gellert, R., & Gutwirth, S. (2013). The legal construction of privacy and data protection. Computer Law & Security Review, 29(5), 522-530. doi: 10.1016/j.clsr.2013.07.005
Han, J., Kamber, M., & Pei, J. (2011). Data mining concepts and techniques third edition. Morgan Kaufmann.
Jakhar, D., & Kaur, I. (2020). Artificial intelligence, machine learning and deep learning: definitions and differences. Clinical and experimental dermatology, 45(1), 131-132.
Kunhn, T.S. (1992). La estructura de las revoluciones científicas, Madrid, ed. Fondo de cultura económica.
Maksabedian, J. (1980). El proceso social en la innovación y la transferencia tecnológica. Revista latinoamericana de psicología, 12(1), 109-117.
Miguel, C. R. (1994). En torno a la protección de los datos personales automatizados. Revista de estudios políticos, (84), 237-264.
Nisa Ávila, J. A. (2016). Robótica e Inteligencia Artificial ¿legislación social o nuevo ordenamiento jurídico? Revista El Derecho, Francis Lefebvre.
Pierini, A. Lorences, V. Tornabene, M. (2002) Habeas data. Derecho a la intimidad, 2ª ed., Editorial Universidad, Buenos Aires.
Ríos Hilario, A. B., Martín Campo, D., & Ferreras Fernández, T. (2012). Linked data y linked open data: su implantación en una biblioteca digital. El caso de Europeana.
Sokolovska, A., & Kocarev, L. (2018). Integrating technical and legal concepts of privacy. Ieee Access, 6, 26543-26557.
World Internet Users Statistics and 2019 World Population Stats. (2019). Retrieved 18 February 2020, from https://www.internetworldstats.com/stats.htm
ElDerecho.com no comparte necesariamente ni se responsabiliza de las opiniones expresadas por los autores o colaboradores de esta publicación